نتایج
برای ارزیابی فرضیه اصلی خود، یک تحلیل رگرسیون لجستیک چندگانه را با استفاده از پنج متغیر پیشبینیکننده شرحدادهشده در بخش روشهایمان (محدوده ملودیک، تکرار، فواصل ملودیک کوچک، تنوع ریتمیک و نسبت مدت زمان طولانی) انجام دادیم تا دوره زمانی را پیشبینی کنیم. آهنگ های 50 سال مدنظر بوده است. songs (دهه 1960 یا 2010.) نتایج تجزیه و تحلیل در جدول 1 در زیر خلاصه شده است.
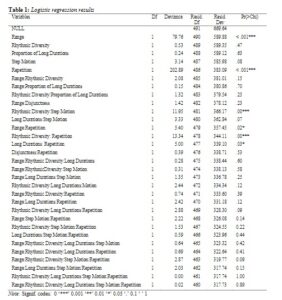
از پنج متغیر اصلی که فرض کردیم به «آهنگ بودن» ها songs مربوط میشوند، تنها دو متغیر تفاوت قابلتوجهی را بین آهنگهای دهه 1960 و آهنگهای امروزی نشان دادند: محدوده ملودیک و تکرار (هر دو p < 0.05؛ شکل 1 را ببینید).
با این حال، جالب توجه است که متغیر محدوده رنج در جهت معکوس چیزی بود که پیشبینی میکردیم، و نشان میداد که آهنگهای songs پاپ مدرن در مقایسه با آهنگهای songs پاپ قبلی، در واقع محدوده بزرگتری دارند.
چهار تعامل نیز قابل توجه بودند: تنوع ریتمیک و فواصل ملودیک کوچک، دامنه و تکرار، تنوع ریتمیک و تکرار، و نسبت مدت زمان طولانی و تکرار (نگاه کنید به شکل 2). با این حال، ما هیچ فرضیه پیشینی در مورد این تعاملات ارائه نکردیم. علاوه بر این، اهمیت موسیقایی این تعاملات به وضوح مشهود نیست.
نکته قابل توجه تفاوت بسیار کوچک در تکرار بین دو گروه دوران است. یعنی، در حالی که به نظر می رسد آهنگ های songs پاپ مدرن از درجه تکرار بیشتری استفاده می کنند، همانطور که در شکل 1 نشان داده شده است، به نظر می رسد میزان افزایش تکرار بسیار کم است.
شایان ذکر است که روش شناسی ما قادر به تمایز بین تکرار کوتاه مدت و بلند مدت نیست. (به عنوان مثال، AABB به همان اندازه ABAB تکرار می شود)
شکل 1 – متغیرهای اصلی مهم – دو مورد از پنج متغیر اصلی “آهنگ بودن” که با موفقیت دوران را پیشبینی کردند (دهه 1960 در مقابل دهه 2010): تکرار (که با فشردهسازی دادهها اندازهگیری میشود)، و محدوده چرخشی.
با این حال، محدوده (سمت راست) برای دوره 2010 که از H1 پشتیبانی نمیکند، بهطور قابلتوجهی بیشتر بود. (برای توضیحات در مورد نحوه محاسبه دامنه چرخش و تکرار به صفحات 122-123 مراجعه کنید). بررسی تجربی موسیقی شناسی جلد. 17، شماره 2، 2022

شکل 2 – تعاملات مهم – چهار تعامل مهم پیش بینی کننده دوران (دهه 1960 در مقابل 2010): تنوع ریتمیک و فواصل ملودیک کوچک (بالا سمت چپ)، دامنه و تکرار (بالا سمت راست)، تنوع و تکرار ریتمیک (پایین سمت چپ)، و تکرار و مدت زمان طولانی (پایین سمت راست).
در مجموع، با توجه به اینکه تنها یکی از پنج فرضیه ما دارای شواهد تجربی بود، ما استدلال میکنیم که دادههای ما از این نتیجهگیری که «ملودی مرده است» یا ملودیهای مدرن کمتر از ملودیهای قبلی هستند، پشتیبانی نمیکند.
نتایج اکتشافی: دادههای جمعآوریشده برای هر یک از در دهههای 1960 تا 2019، ما همچنین یک تجزیه و تحلیل پسهک از روند متغیرهای آهنگین خود انجام دادیم. بررسی کند که آیا این تغییرات تدریجی، ناگهانی بوده یا ممکن است در سالهای میانی تغییر جهت داده باشد.
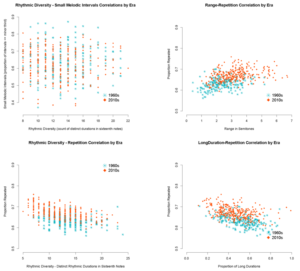
ما یک رگرسیون خطی برای هر متغیر انجام دادیم و داده ها را ترسیم کردیم تا ببینیم آیا می توان روندی را مشاهده کرد. شکل 3 تمام مقادیر را برای هر یک از پنج متغیر خوش آهنگی همراه با خط بهترین تناسب برای طیف کامل سالها از 1960 تا 2019، شامل ترسیم میکند.
شکل 3 – تجزیه و تحلیل پستی خطی – هنگام بررسی مجموعه کامل داده ها بر اساس دهه، اثرات قابل توجهی برای تکرار (بالا سمت چپ)، دامنه (بالا سمت راست)، تنوع ریتمیک (وسط سمت چپ) و نسبت مدت زمان طولانی (وسط سمت راست) پیدا کردیم. . روند متغیرهای تکرار و تنوع ریتمیک در جهت پیشبینیشده ما مطابق با فرضیههای 2 و 4 بود.
با این حال، دامنه متغیرها و نسبت مدتزمانهای طولانی در جهت معکوس با فرضیههای 1 و 5 مغایرت داشتند. متغیر پنجم (نسبت فواصل ملودیک کوچک) قابل توجه نبود بررسی تجربی موسیقی شناسی جلد. 17، شماره 2، 2022
البته، هیچ دلیلی وجود ندارد که فرض کنیم هر گرایش موسیقایی خطی خواهد بود، و همیشه می توان تلاش کرد تا یک خط مستقیم را در نظر بگیرد. با این وجود، ما اثرات قابل توجهی برای تکرار و دامنه (مانند قبل)، بلکه برای نسبت مدت زمان طولانی و تنوع ریتمیک پیدا کردیم.
این احتمال وجود دارد که دادههای اضافی در مدلهای خطی، تفاوت نتیجه لجستیکی ناچیز به نتیجه مدل خطی قابل توجه در حدود را توضیح دهد.


بحث هر سازنده موسیقی محبوب می خواهد بتواند موفقیت بزرگ بعدی را پیش بینی کند. در زمینه انفورماتیک موسیقی، تلاش برای کشف آناتومی آنچه که یک آهنگ موفق را ایجاد می کند، به عنوان علم آهنگ های songs موفق شناخته می شود.
یکی از جنبه های مورد مطالعه ترانه، ملودی است، با این باور عمومی که کلید یک آهنگ عالی نوشتن یک ملودی عالی است (فردریک، 2019).
فرض ضمنی این است که یک «قلاب» عالی، جذاب و به یاد ماندنی است (Burgoyne، 2013)، و تحقیقات ادراکی نشان داده است که ملودیهای آشنا از نظر زیباییشناختی دلپذیرتر از ملودیهای ناآشنا هستند (Janssen et. al, 2017).
همچنین پیشنهاد شده است که یک “نقطه شیرین” بهینه از نظر تکرار آهنگ وجود دارد. تکرار بیش از حد و آهنگ به عنوان “خسته کننده” یا احتمالاً “آزاردهنده” تلقی می شود، در حالی که فراوانی بیش از حد مواد جدید می تواند باعث شود که آهنگ بسیار پیچیده تلقی شود، با این ایده کلی که افزایش تکرار منجر به تسهیل در پردازش ذهنی موسیقی (هورون، 2006). این با یافته Cheung و همکاران (2019) مطابقت دارد که نشان داد محتوای اطلاعات و آنتروپی به طور قابل توجهی علاقه به دنبالههای وتر را پیشبینی میکنند.
یک مشاهده به ظاهر متناقض این است که، طبق نتایج ما، به نظر میرسد که آهنگها songs به طور فزایندهای تکرار میشوند، اما با توجه به اینکه آهنگها همه «هیتها» هستند، احتمالاً تکرار با علاقه مرتبط است.
صنایع انتشارات تنها محرکها در خلق آثار نیستند، بلکه عموم مردم باید از آنها لذت ببرند.) در واقع، مقاله اخیر آلبرشت (2019) تفاوتی در تکرار حتی بین آهنگهایی songs که همه پرطرفدار هستند (کنترل برای سال) نشان داد و نشان داد که آهنگهای بالای نمودارهای بیلبورد دارای تکرار بیشتری نسبت به آهنگهای songs پایین جدول هستند.
در حالی که مقاله کنونی مطالعهای درباره خاطرهانگیزی یا «جاذبه» نبود، نتایج ما نشان میدهد که روند کمی به سمت افزایش تکرار وجود دارد که (طبق تعریف ما) بیآهنگ است، اما ظاهراً در یک آهنگ محبوب مدرن مطلوب است.
ملودیهای یک نت در آهنگ ها songs
حداقل بر اساس تعریف بیلبورد از آنچه که یک آهنگ برتر 100 آهنگ برتر را می سازد. با این حال، ما هیچ شواهد تجربی برای حمایت از این ادعا پیدا نکردیم که «ملودیهای یک نت» در نمونهای از آهنگهای songs پاپ مدرن رایج هستند، زیرا هیچ تفاوتی در شیوع فواصل ملودیک کوچک در بین گروهها وجود نداشت.
با توجه به روش شناسی تجزیه و تحلیل پیکره ما، چندین هشدار ضروری است. اول، ممکن است استفاده از الگوریتمهای رونویسی خودکار، رونویسی ملودی را به اندازه کافی دقیق برای جمعآوری تصویری منسجم از روندهای واقعی یا تغییرات موسیقی در طول زمان ارائه نکند.
با این حال، همانطور که گفته شد، سابقه ای برای استفاده از “داده های آشفته” وجود دارد. یعنی، فرض میکنیم که خطاهای ملودیها بهطور تصادفی در طول دوره زمانی مجموعه کامل ما توزیع شدهاند، و به این ترتیب، هنگام بررسی چنین حجم زیادی از دادهها برای بررسی روندهای بسیار گسترده، احساس میکنیم که دادهها، در حالی که مطمئناً خطا دارند.
مستعد، نتایج قابل اعتمادی می دهد. ما استفاده از رونویسی خودکار را برای “خواندن نزدیک” یا تحقیقات سنتی تر موسیقی-نظری توصیه نمی کنیم. ثانیاً، به خوبی میتوان گفت که رویکردهای سیستماتیک ما برای جذب متغیرهای مورد علاقهمان مناسبترین نبودند.
و در آخر، ممکن است سایر ویژگی های ملودیک بینش بهتری ارائه دهند. به عبارت دیگر، ممکن است تعاریف عملیاتی ما از «آهنگ بودن» songs به طور کلی ضعیف تصور شده باشد یا به احتمال زیاد، به سادگی ناقص باشد.
با این حال، ما امیدواریم که این تجزیه و تحلیل به عنوان اثبات مفهومی برای انواع پرس و جوهایی که با استفاده از این نوع داده ها امکان پذیر است، عمل کند.
علاوه بر این، ما اشاره کردیم که در حالی که استفاده از فشرده سازی به عنوان یک پروکسی برای تکرار ملودیک در ارزیابی یک تعمیم گسترده مانند آنچه در اینجا در نظر گرفته شده مفید است، بینش کمی در مورد انواع تکرار ملودیک (مانند دنباله های ملودیک، جابجایی، وارونگی، رتروگراد، پسوندها، الیزیون ها و غیره) در طول سال ها یا در سبک های مختلف استفاده می شوند.
در نهایت، یک تحلیل بزرگتر اما پیچیده تر که ملودی را در زمینه هارمونی، فرم یا ژانر در نظر می گیرد، ممکن است بینش های معنی داری را نشان دهد. تحقیقات بیشتری برای تعیین تأثیر این عناصر ملودیک بر سبک های موسیقی رایج مورد نیاز است.
بهترین آموزشگاه موسیقی ( Music Institute ) در غرب تهران 1403 (West Tehran )